
https://www.w3schools.com/ (백엔드 개발자들이 많이 이용하는 사이트)
크롤링(crawling)은 웹페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위.
스크레핑(scraping)은 원하는 정보만 가져와 데이터를 추출해 내는 행위
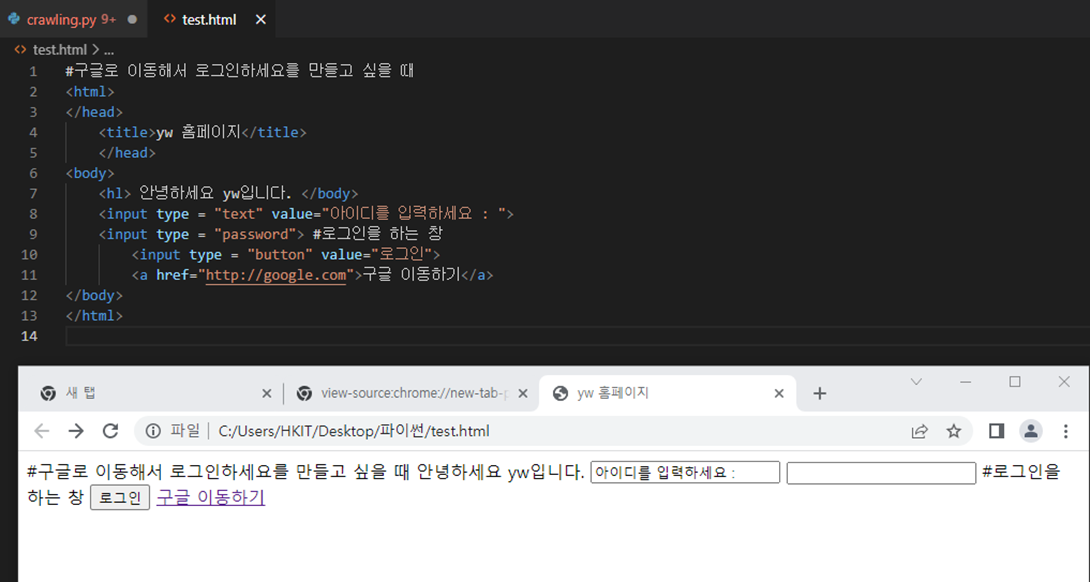
#구글로 이동해서 로그인하세요를 만들고 싶을 때
<html>
</head>
<title>yw 홈페이지</title>
</head>
<body>
<hl> 안녕하세요 yw입니다. </body>
<input type = "text" value="아이디를 입력하세요 : ">
<input type = "password"> #로그인을 하는 창
<input type = "button" value="로그인">
<a href="http://google.com">구글 이동하기</a>
</body>
</html>
# xpath(XML path language)
import requests
from requests import status_codes
res = requests.get("http://naver.com")
res.raise_for_status()
#print("응답 코드 :", res.status_code)
print(len(res.text))
print(res.text)
with open("mynaver.html", "w", encoding="utf8") as f:
f.write(res.text)위와 같이 작성하고 나면

html파일이 자동으로 생긴다.
이 파일을 열어보면
내용이 긴 파일이 생긴다.
# xpath(XML path language)
import requests
from requests import status_codes
# res = requests.get("http://naver.com")
# res.raise_for_status()
# #print("응답 코드 :", res.status_code)
# print(len(res.text))
# print(res.text)
# #with open("mynaver.html", "w", encoding="utf8") as f:
# # f.write(res.text)
url = "http://instagram.com"
res = requests.get(url)
res.raise_for_status()
with open("edusahre.html", "w", encoding="utf8") as f:
f.write(res.text)
이런식으로 파일이 생긴다.
파일을 또 열어보면

인스타그램 url을 입력했기 때문에 인스타그램의 소스들이 보인다.
user agent 보는 방법
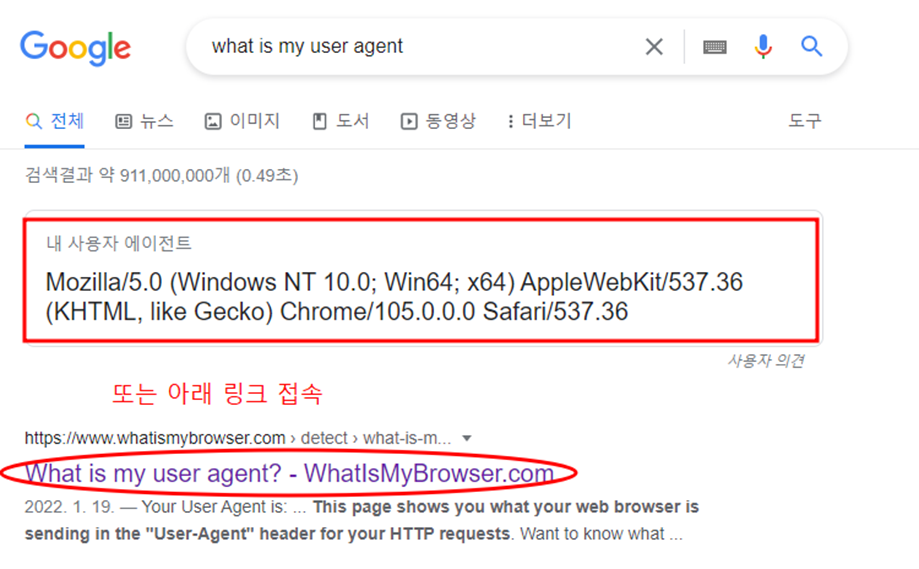

해당 유저에이전트 정보 복사한 뒤 파이썬 변수입력란에 집어넣기
# xpath(XML path language)
import requests
from requests import status_codes
url = "http://instagram.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
res = requests.get(url, headers=headers)
#웹페이지 요청 시 정상적으로 소스를 긁어오지 못할 때
res.raise_for_status()
with open("edusahre.html", "w", encoding="utf8") as f:
f.write(res.text)
빅데이터 분석
요구사항 분석 -> 데이터 수집 -> 데이터 전처리(분석용이) -> 데이터분석 및 시각화
daum_moive.py(파일명 아무거나) 생성
daum.net
2020년 영화 순위 검색 후 주소창 주소 복사
pip 명령어로 BeautifulSoup4 설치
사이트로 돌아와서 개발자 도구 열기
선택 버튼 클릭


클릭 후 아무 이미지 (여기서 남산의 부장들 클릭함)를 클릭하게되면 해당 이미지에 대한 개발자 도구가 나오게 된다.

이제 이미지를 이용해서 찾아본다.
pip install lxml 명령어 사용해서 설치
import requests
from bs4 import BeautifulSoup
res = requests.get("https://search.daum.net/search?w=tot&DA=UME&t__nil_searchbox=suggest&sug=&sugo=15&sq=2020sus+du&o=2&q=2020%EB%85%84+%EC%98%81%ED%99%94+%EC%88%9C%EC%9C%84")
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
#이미지 변수 삽입
image = soup.find_all("img", attrs={"class": "thumb_img"}) #2가지 이상을 찾고 싶을 때는 find_all
(명령어 순서는 아래 이미지 참고)
실행해보면 에러는 안뜨지만 나오는 것은 아직 없다.

이제 이 상위 5개의 이미지를 가져올건데 반복적인 작업을 할거라서 반복문을 사용하면된다.
이미지 스크래핑
import requests
from bs4 import BeautifulSoup
res = requests.get("https://search.daum.net/search?w=tot&DA=UME&t__nil_searchbox=suggest&sug=&sugo=15&sq=2020sus+du&o=2&q=2020%EB%85%84+%EC%98%81%ED%99%94+%EC%88%9C%EC%9C%84")
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
#이미지 변수 삽입
images = soup.find_all("img", attrs={"class": "thumb_img"}) #2가지 이상을 찾고 싶을 때는 find_all
for idx, image in enumerate(images):
image_url = image["src"]
if image_url.startswith("//"):
image_url = "https:" + image_url
print(image_url)
image_res = requests.get(image_url)
image_res.raise_for_status()
#파일만들기
with open("movie{0}.jpg".format(idx+1), "wb") as f:
f.write(image_res.content)
if idx >= 4: #상위 5개 이미지까지만 다운로드
break

실행하면 파일이 생긴다. 파일을 열어보면 이미지만 스크래핑 가능

네이버웹툰에서 내가 원하는 정보들만 가져오기
naver_webtoon.py 파일 만들기
네이버 웹툰 홈에 들어가서 주소 복사 https://comic.naver.com/webtoon/weekday
복사해줄 때 네이버는 nhn이라는 확장자가 붙기 때문에 아래와 같이 작성
url = "https://comic.naver.com/webtoon/weekday.nhn"
import requests
from bs4 import BeautifulSoup
from os import name
import re
#네이버 웹툰
url = "https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status()
#print(res.text)
soup = BeautifulSoup(res.text, "lxml")
print(soup.title)
print(soup.title.get_text())
print(soup.a) #처음 발견되는 a element 출력
print(soup.a.attrs) #a element의 속성 정보를 출력
print(soup.a["href"]) # a element 속성 중에서 href 값만 출력
print(soup.find("a", attrs={"class": "Nbtn_upload"})) #Nbtn_upload라는 값을 찾아라
#print(soup.find(attrs={"class": "Nbtn_upload"}))
#print(soup.find("a", attrs={"class": "title"}))
#a element 밑에 class 중 title 출력
im = soup.find("a", attrs={"class": "Nbtn_upload"})
print(im.next_sibling) # 다음 element 찾음
print(im.next_sibling.next_sibling) # 다다음 element 찾음
print(im.previous_sibling) #이전 element 찾음

셀렉트 한 다음 웹툰올리기를 클릭해보면 해당 개발자 도구가 뜬다. 그럼 이제 파이썬에 입력


그래서 실행해보면 웹툰올리기 라는 클래스를 잘 찾아낸 것을 볼 수 있다.
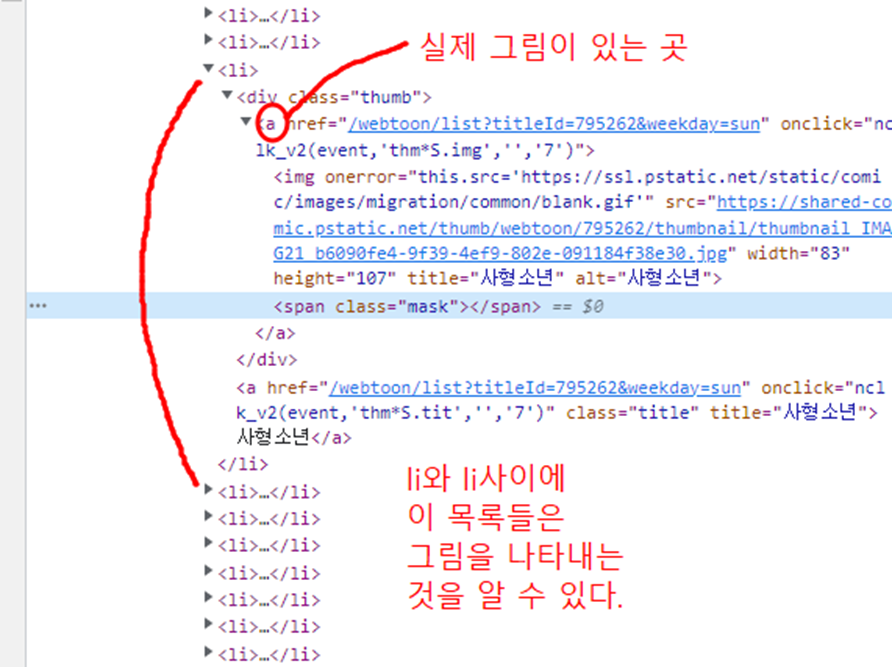


url = "https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
#전체목록 가져오기
webtoons = soup.find_all("a", attrs={"class": "title"})
print(webtoons)
만화의 전체목록 조회가능
url = "https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
#전체목록 가져오기
webtoons = soup.find_all("a", attrs={"class": "title"})
print(webtoons)
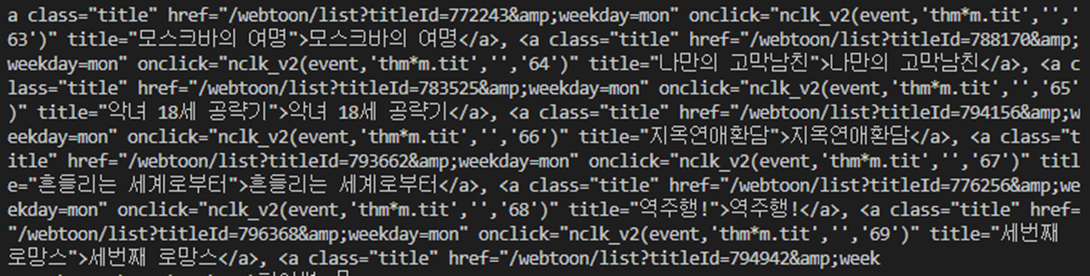
for webtoon in webtoons:
print(webtoon.get_text())
텍스트정보(만화제목)만 출력해서 가져오는 것 가능

사형소년 - 만화제목과 실제 링크 가져오기
https://comic.naver.com/webtoon/list?titleId=795262&weekday=sun 링크
웹페이지로 가서 셀렉트 모드 후 회차 이미지 클릭


#사형소년 - 만화제목 + 실제 링크 가져오기
url = "https://comic.naver.com/webtoon/list?titleId=795262&weekday=sun"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
boy = soup.find_all("td", attrs={"class":"title"})
#td인 태그의 속성 값에서 클래스가 executionboy인 것을 추출해라
title = boy[0].a.get_text()
link = boy[0].a["href"]
print(title)
print(link)
print("https://comic.naver.com" + link)

평점 구하기
셀렉트 모드 후 평점을 클릭하면

# 사형소년 평점구하기
url = "https://comic.naver.com/webtoon/list?titleId=795262&weekday=sun"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
t_score = 0
webtoons = soup.find_all("div", attrs={"class": "rating_type"})
print(webtoons)
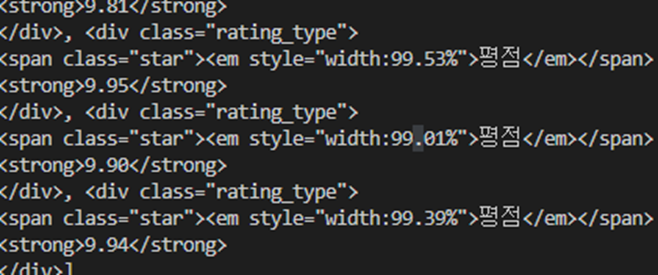
텍스트만 가져오기
# 사형소년 평점구하기
url = "https://comic.naver.com/webtoon/list?titleId=795262&weekday=sun"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
t_score = 0
webtoons = soup.find_all("div", attrs={"class": "rating_type"})
print(webtoons)
for webtoon in webtoons:
rate = webtoon.get_text()
strong 태그에 있는 텍스트 정보만 가져오기
url = "https://comic.naver.com/webtoon/list?titleId=795262&weekday=sun"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
t_score = 0
webtoons = soup.find_all("div", attrs={"class": "rating_type"})
print(webtoons)
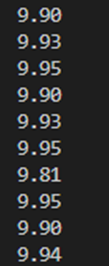
for webtoon in webtoons:
rate = webtoon.find("strong").get_text()
print(rate)
url = "https://comic.naver.com/webtoon/list?titleId=795262&weekday=sun"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
t_score = 0
webtoons = soup.find_all("div", attrs={"class": "rating_type"})
print(webtoons)
for webtoon in webtoons:
rate = webtoon.find("strong").get_text()
print(rate)
t_score = int(t_score + float(rate))
print("전체 점수 : ", t_score)
print("전체 점수 : ", t_score / len(webtoons))

'정보보안실무 > 웹' 카테고리의 다른 글
| PHP function 함수와 php파일 삭제, 읽기, 쓰기 (0) | 2023.05.06 |
|---|---|
| PHP 조건문, 반복문, for문 (0) | 2023.05.06 |
| PHP 연산자 구성과 데이터 입력 받는 방법 (0) | 2023.05.06 |
| 웹(WEB) 기본 동작 개념 (0) | 2023.05.05 |
| 웹브라우저 자동화모듈 설치 (0) | 2023.04.16 |